I joined Collab and began working on adding a second data source to the recently acquired TrendPop’s platform. As a somewhat of a content creator myself, it’s been really exciting to have worked so closely to the creator economy.
Highlights
- Analyzed the most efficient way to extract data from YouTube
- Used Golang to write an efficient abstraction for forging YouTube’s unofficial API
- Designed and implemented scalable jobs with Apache Spark to track and discover new entities
- Extracted and stored over 1 billion total records including: videos, channels, playlists, and comments
- Automatic reporting of metrics associated with the code sent to Grafana
Internship Overview
My internship consisted of 3 main parts: creating an engineering proposal plan, implementation, and finally a presentation open to the entire company which included some execs.
Engineering Proposal Plan (~4 weeks)
The goal of creating this proposal was to align the entire team with what I would be doing over the summer and the tools and methodologies I would use to accomplish it. This part of my internship included
- Researching and prototyping ways to extract data from YouTube
- Researching the best technologies to use for the job
- Analyzing all tradeoffs and risks to my approach
The most important thing to research was how to best extract data from YouTube. I settled on using a technique that I call forging API requests, in which you make requests that look identical to what a legitimate client would make to the backend server. Since most websites do use the AJAX approach, this is pretty effective on most websites. This approach has significant tradeoffs compared to a traditional HTML based web scraping approach, if you want to learn more about this approach check out lesson 1 in my everything-web-scraping series. The largest one is the lack of control over changes that the 3rd party makes to their API, I used commit history on youtube-dl to see how frequently the API changed and it seems to be pretty rare where it was acceptable to use this method.
Implementation & Productionizing (~6 weeks)
- Introduced Apache Spark as a new technology used within the platform
- Intelligent metric reporting for debugging jobs
- Visualized metrics and created alerts in Grafana
- Working through dozens of edge cases and improving data parsers
While investigating the best tools for the job, it was decided on that I should look into Apache Spark. It fit our use case perfectly. It allows us to easily scale our jobs across multiple threads and in the future if needed across multiple computers/executors if extremely computationally expensive.
One important thing was to ensure that there was good visibility onto what these jobs were doing as it’s always a challenge to maintain and debug these kinds of programs that are so dependent on third party API responses with countless edge cases. To increase the ease of debugging on all the jobs, I reported metrics around failing API requests, parsing failures, and any postgres errors to telegraf which communicates with an influxdb instance that Grafana pulls data from. Here’s a screenshot of one of the dashboards within Grafana I created.
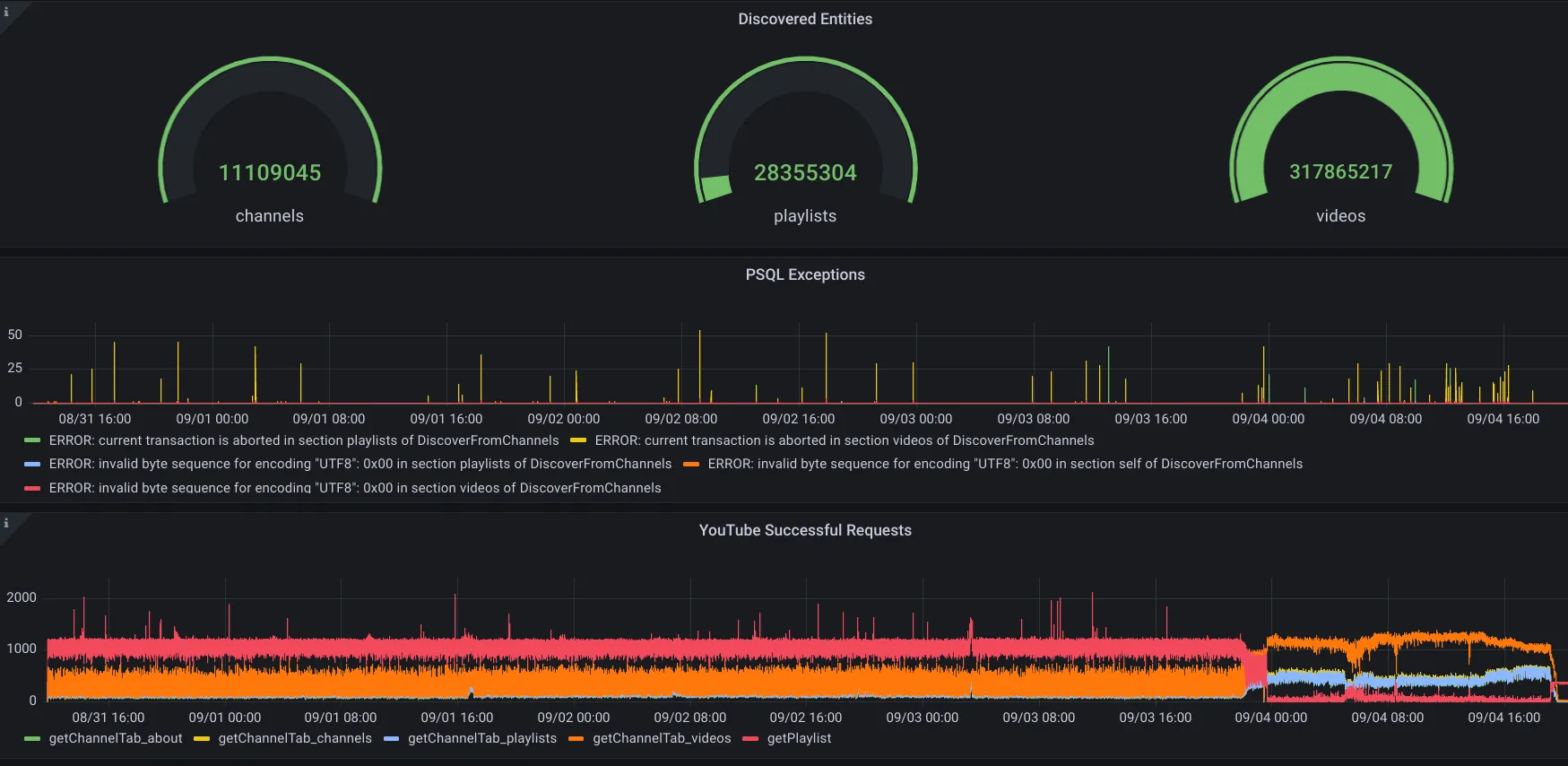
The last thing I’ll talk about for this section was the pain of slowly working through dozens of edge cases since the “hidden” YouTube API is not officially documented and returns a lot of different types of structures like compactVideoRenderer vs videoRenderer which is awfully annoying to deal with.
Presentation (~1 week)
Unfortunately, I can’t share the exact slides here. This presentation dove into case studies on how this new YouTube data could help a new potential customer. Next, was how the data could help Collab creator Zhong better understand their audience and how to further optimize their content strategy.
To answer all these questions, I spent this entire week relying heavily on my data science skills writing complex SQL queries and running more data-intensive code with python making heavy use of the pandas package to deliver some interesting insights into YouTube.
What I Learned
- How Apache Spark works and why it’s great for computationally expensive jobs
- Scala as a programming language
- When parsing 3rd-party API responses never assume anything about the structure of the response
- Even however hard you try to not assume anything you’ll still run into weird edge cases at scale
- Postgres isn’t ideal for the amount of data we needed to store
- Engineering time was designated in a later quarter to switch to a distributed database like Cassandra
- Grafana is really useful to analyzing jobs and exactly what they’re doing at scale especially with exceptions are handled and retry-logic is built-into the jobs to ensure that the job just continues running no matter what
- I used Grafana in the summer of 2021 with Warner Music Group, but I wasn’t usually the one using the metrics to debug the jobs.
Overall, I had a great time and enjoyed working so closely with the creator economy.